一言以蔽之:監督式學習是最基礎的人工智慧。
AI(Artificial Intelligence)人工智慧在上個世紀的1950年代就開始發展了,不過真的比較開始熱門起來應該是從1990年代起開始大量使用neural network,畢竟當時電腦已經開始普及了。當年的題目比較單純,就是做一些supervised learning(監督式學習),其中最常見的就是classification了。
MNIST可以說是分類的濫觴,也是AI初學者寫TensorFlow或PyTorch的的第一個作業,目的就是把手寫郵遞區號的圖案分類出0~9的數字。

以前我們要寫分類的程式,就是想辦法找出規律,然後寫一大堆if-else判斷邏輯,如果發現有特例,再繼續寫更複雜的if-else。不過讓我們回想幼兒園教小朋友認識數字時,並不是用if-else教小朋友的,而是就給小朋友很多數字卡片,說這是0、這是1、這是2……,等小朋友看多了,他就自然而然地學會了。這時候老師在白板上寫一個1,雖然不在小朋友看過的字卡內,但小朋友也答得出來。
小朋友的頭腦就像一張白紙,裡面很多神經元,隨著閱讀字卡,就把神經元之間的連線建立起來了,於是就學會判讀數字圖案。一樣的做法,電腦的neural network就是模仿大腦的認知方式,矩陣的element是神經元、weight是連線的強度,然後我們丟給電腦許多字卡(也就是labeled data),電腦就會從這些大數據去訓練適當的weight,下次它看到新的圖案時,它就會用這個事先訓練好的weight去判斷新圖案是什麼數字。
# Reference: https://www.tensorflow.org/tutorials/quickstart/beginner import tensorflow as tf # 組建一個神經網路 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10) ]) # 選擇loss function loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy']) # 載入MNIST數據 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # 用大數據去訓練 model.fit(x_train, y_train, epochs=5)
上面這就是MNIST的TensorFlow程式,程式碼很短,簡單地說就是對model的weight偏微分,找出loss function最小值,說白了就是在做maximum likelihood而已。如果去看weight的visualization,會發現這類的neural network就是在找特徵:
- 比如最簡單的特徵如下:
- 有「l」的是1,4,5,6,7,9
- 有「o」的是0,6,8,9
- 有「ɔ」的是2,3,5
- 進一步就是特徵的組合,例如:
- 只有一個「o」的就是0
- 上下二個「o」的就是8
- 有「l」又有「o」,「l」在「o」左邊就是6,「l」在「o」右邊就是9
下圖是一個CNN(convolutional neural network)的例子(取自An Intuitive Explanation of Convolutional Neural Networks),該網頁中有更清晰的圖來說明特徵(也就是feature map)。
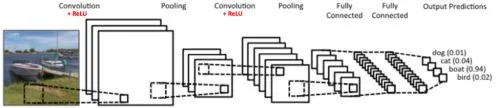
監督式學習,就是拿大量已被人類標註過正確答案的資料,給機器學習,前面說的手寫郵遞區號就是給典型的例子,這種機器學習並不會無中生有,所以我們會發現「i」和「!」這二個圖案都會被誤認成數字「1」。雖然不會無中生有,但用在判斷上,也是相當有幫助的,比如說幫助醫生判讀X光片,有病還是沒病。