一言以蔽之:焦點會捕捉你的眼球,就是所謂的吸睛。

左上角這張照片是禁止任何車輛進入的標誌,本來是「—」的符號,被人貼上二點白色貼紙,人們一眼就看到這個「÷」除法符號,但很少人注意到後面有高架橋、旁邊有草坪。也就是說,人眼看到的畫面像是右上角的照片。
攝影教學網站常教大家拍「淺景深」照片的技巧,使用「大光圈、長焦段,鏡頭盡量靠近主體、遠離背景」,就是為了形成這樣的照片,幫助人眼過濾掉不重要的資訊。
人類在看照片的時候,並不是看整張圖,而是會把注意力放在焦點上,這就是attention。AI是模擬人類的智慧,自然也會有attention,最簡單的應用,就是給電腦一張照片,它會對這張照片下標題,在TensorFlow的教學網站,就有image captioning這樣的範例程式。這個神經網路如下圖,簡單地說,人眼一開始先看到surfer和wave,最後再前後文接成『A surfer is surfing on a wave.』。
# Reference: https://www.tensorflow.org/tutorials/text/image_captioning # model分成三部分 # (1) Input - The token embedding and positional encoding. # (2) Decoder - A stack of transformer decoder layers where each contains: # (a) CausalSelfAttention - each output location can attend to the output so far; # (b) CrossAttention - each output location can attend to the input image; # (c) FeedForward - further processes each output location independently. # (3) Output - A multiclass-classification over the output vocabulary.
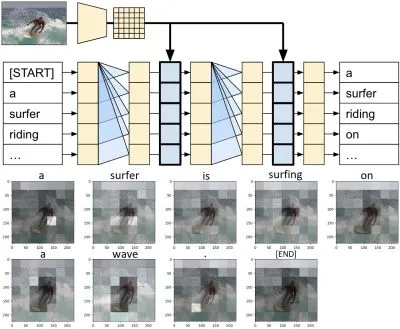
和RNN(recurrent neural network)相比,由於RNN是循環的,會依賴上一個時間的計算結果,所以不能並行處理,但attention可以平行運算。另外,長時間後RNN會忘記前面的資料,因為人腦是短期記憶的,但attention是抓重點,就算忘記前面細節也不會丟掉重點。
attention除了在電腦視覺處理裡面很重要的技巧,其實在語言裡面也是。我們是非英文母語者,可以輕易聽得懂自己同事的英文,但卻完全聽不懂外國人的英文,覺得母語者講英文講很快。其實他們不是說話速度快,而是會連音並輕讀不重要的母音,比如母語者在講『I want to eat an apple.』這句話的時候,會變成『aI wantə itən æpl』,會帶過不重要的文法字,只保留stress在『want eat apple』,如果我們能把注意力放在這些stressed word,就會聽懂母語者在講『吃蘋果』。