一言以蔽之:利用生成、對抗兩個網路相互競爭來產生大量的訓練數據。
想像有個假鈔製造家『畫家』,一開始用印表機印製假鈔,把這種假鈔和真鈔一起放進驗鈔機,驗鈔機可以很輕易地認出假鈔。於是畫家就開始改良印刷方式,改用凸版微縮印刷,並用變色墨水,看起來已經很像真的,結果還是通過不了驗鈔機,因為摸起來的紙質不對。畫家再繼續改良,不用一般紙,而是棉和亞麻混入紅藍色纖維,最後成功地製作出驗鈔機抓不出來的完美的美元偽鈔——「超級美鈔」。(按:有興趣的人可以參考電影《無雙》。)
在這架構中,畫家就是生成模型generative model,而驗鈔機就是判别模型discriminative model。生成神經網路G不斷地模仿樣本真鈔來輸出假鈔,另一個判別神經網路D就挑剔G印出來的東西,一直訓練到D無法區分是本來訓練樣本裡面的真鈔、還是G生成的假鈔。簡單架構如下圖所示:
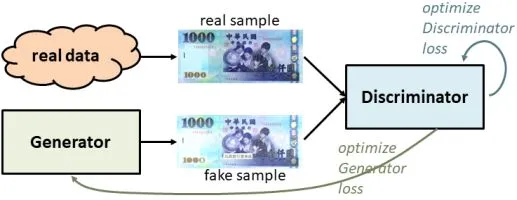
這種透過兩個神經網路相互競爭的方式來進行機器學習,就是生成對抗網路generative-adversarial network,縮寫為GAN。每次課堂上教到這個,大家都會會心地一笑,因為GAN的發音與中文的髒話『幹』相近。
GAN的一個重要優點就是它是非監督式unsupervised學習,再也不用人為標註資料了。訓練人工智慧需要大量的資料,在一些無法獲得大量資料的領域來說(例如有隱私考量的個人資料或是本來就少的yield loss sample),GAN以假亂真就可以編造出足夠多的的數據。