一言以蔽之:Transformer是目前最成功的自然語言處理模型。
在natural language processing中,早年是用RNN(recurrent neural network),但由於RNN不能平行運算、而且會忘記先前的記憶,所以就有一些改進的版本,像是LSTM(long/short-term memory)和GRU(gated recurrent unit)。
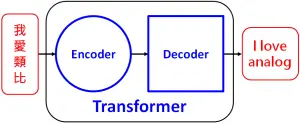
近年來又發展出transformer的深度學習模型,這架構就像變形金剛一樣厲害(按:變形金剛玩具的英文就是Transformers),在自然語言處理領域產生了重大影響,並促成了能夠執行廣泛語言任務的模型。知名的ChatGPT就是一個Generative Pre-trained Transformer模型,剛出現就一炮而紅,有多紅呢?根據World of Engineering的推特,ChatGPT的用戶數量僅僅在二個月就飆破一億人。(按:這個記錄在2023年7月就被破了,Threads登場僅僅五天,全球註冊人數就超過一億人。)
| 服務 | 用戶達一億人所花的時間 |
|---|---|
| 電話 | 75年 |
| 手機 | 16年 |
| 全球資訊網(WWW) | 7年 |
| iTunes | 6.5年 |
| 5年 | |
| 4.5年 | |
| 3.5年 | |
| 2.5年 | |
| Apple App Store | 2年 |
| ChatGPT | 2個月 |
| Threads | 5天 |
transformer模型,就如同它的論文標題『Attention is All You Need』,這架構利用encoder負責self-attention和feed-forward layer來處理輸入序列,再利用decoder來生成輸出序列,也就是通過計算句子中每個詞的注意力分數來權衡句子中不同詞的重要性,來將input sequence『轉換』為output sequence,因此命名為轉換器transformer。
GPT使用的transformer模型,則是有些小改變,它把encoder裡面的self-attention換成了masked self-attention,這裡所謂的masked就是每個詞只能對自己前面的詞進行attention(本來的self-attention是每個詞都可以看到自己前後的所有詞),如此就可以使用大量unlabeled的文章進行pre-training。
接著就一直一直餵給GPT模型許多網路上的文本,像是維基百科、新聞網站這類的權威文章。想像如果有一個人讀萬卷書,最後他自然能根據之前看過的資料來回答user的問題、依照user的提詞來續寫故事……,而這個就是ChatGPT。